
Fine Tuning
: transfer-laearning의 일반적인 기술로 기존에 학습되어 있는 모델을 기반으로 아키텍쳐를 목적에 맞게 변형하여 학습된 모델의 파라미터들을 미세 조정하는 방법이다.
Step
: 기본적으로 4단계로 구성한다.
-
사용할 소스 model을 pretrain 시킨다.
- 학습된 모델을 생성한다. 이 때, output layer를 제외한 모델 아키텍쳐와 파라미터들이 복사가 된다.
- output layer를 추가하고, output layer의 파라미터들을 램덤하게 초기화 한다.
- 대상 dataset에서 대상 model을 training 시킨다.
: 이때 , out layer는 처음부터 학습이 되지만, 다른 layer들의 파라미터들은 기존 model의 파라미터들을 기반으로하여 미세 조정한다.
transfer-laearning 과의 차이
-
output layer만 학습하는게 모든층의 파라미터를 재학습 시킨다.
-
input-layer에 가까울수록 learning rate를 작게 설정하고 output-layer는 처음부터 훈련함으로 learning rate를 크게 설정한다.
Strategy
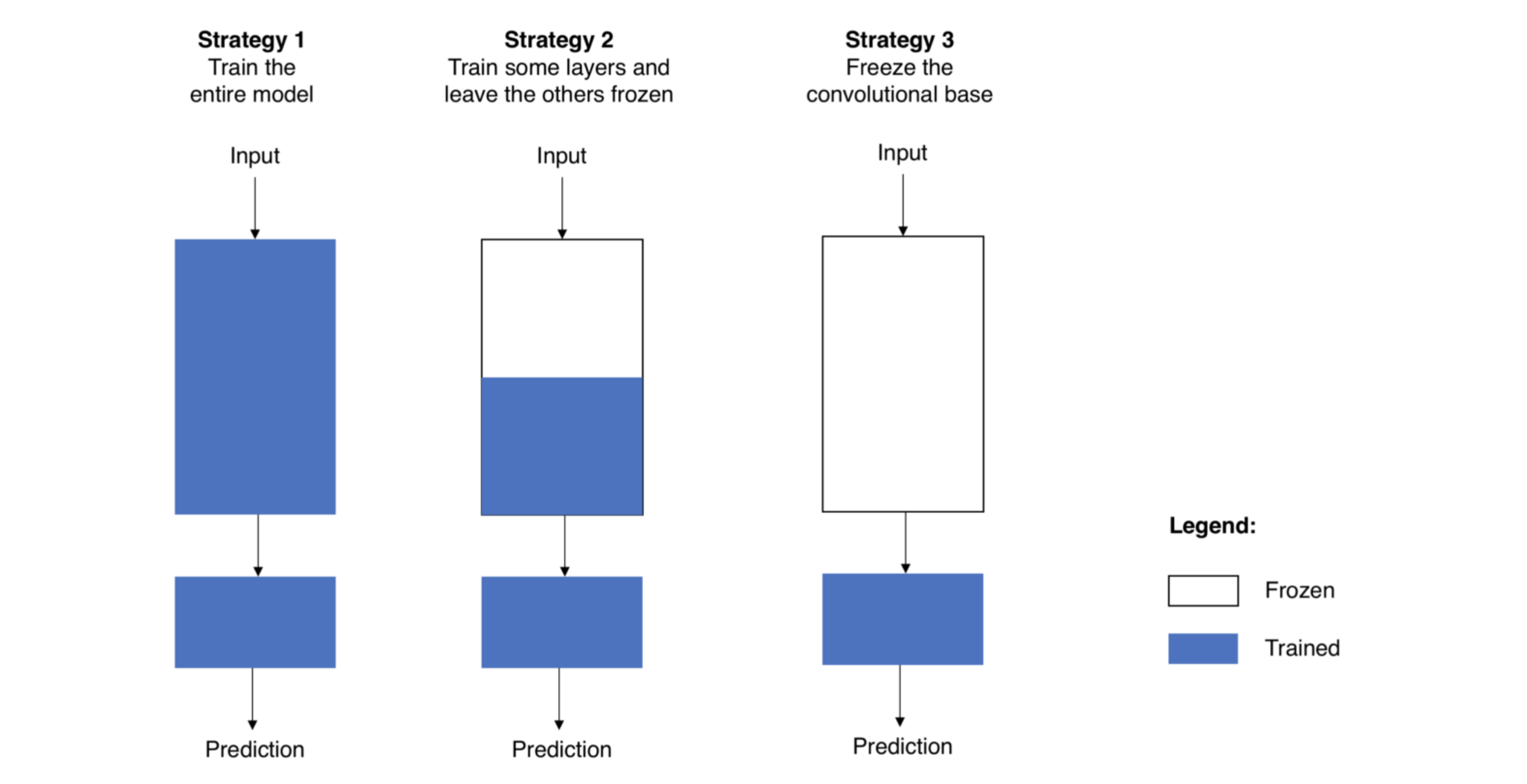
1. 전체 모델을 새로 학습 시키기
- pre-train된 모델의 구조만 사용
- 새로운 dataset에 맞게 전체를 새롭게 학습 시키는 방법
- 밑바닥 부터 학습을 시켜야 함으로 큰 dataset이 필요하다.
2. Convolutional base의 일부분은 고정시킨 상태로, 나머지 계층과 classifier를 새로 학습시키기
-
낮은 레벨 계층은 일반적인 특징을 추출하고 높은 레벨의 계층에서는 구체적인 특징을 추출한다.
- 위 특성을 이용해 재학습시킬 파라미터의 범위를 정한다.
- 여기서 dataset이 작고 모델의 파라미터가 많으면 오버피팅 될 위험성이 있어 더 많은 계층을 건들지 않고 그대로 둔다.
- 반대로 dataset이 크고 파라미터가 적다면 오버피팅의 위험성리 적음으로 더 많은 계층을 학습 시켜 상황에 맞는 모델을 만들 수 있다.
3. Convloutional base는 고정시키고, classifier만 새로 학습시키기
- 이 방법는 특징 추출 메커니즘으로써만 활용하고, classifier만 재학습 시키는 방법이다.
- 이 방법 사용하는 경우
- dataset이 작을때
- 현재 해결해야하는 상황이랑 pre-train된 모델의 dataset이 유사할때 생각해볼 수 있다.
Code
- : https://github.com/Ahnho/DeepLeaning_PJ/blob/main/modern/Fine_Tuning.ipynb
참조
- https://d2l.ai/index.html
- 만들면서 배우는 파이토치 딥러닝, 오가와 유타로 저, 박광수 옮김, 한빛미디어 (2021)
- https://jeinalog.tistory.com/13